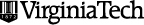Recently a student in the “Digital Past” class I’m teaching posted a link to our Diigo Group which she described as “not very informative” but “interesting.” Listen to Wikipedia be edited: listen.hatnote.com There’s a map, too: hatnote.com
I thought we could do a session where we take 10-15 minutes to just watch the site together, 10-15 minutes to interact with it (choose a different language, click on some of the links, visit the GitHub repo, whatever), and then use the remainder of the time to do some collaborative reflective writing on what we thought, saw, felt, learned. Participad would be a great tool for doing the collaborative writing part if you don’t mind my using my admin privileges to activate it on this site.
Having had the site open in a tab for quite a while on a couple of separate days, I think it actually is very informative — about visualizations, about whatever the audio equivalent of visualizations is, about Wikipedia, about knowledge, about the world. I’m also generally interested in similar sorts of interactive art / games / projects built on functional internet tools: GlobeGenie and Twistori come to mind. We could have a discussion, of course, but for some reason I’m keen on the idea of a completely silent session …